Missing
- Wordfish
- Rescaling
- Bag of words assumption
- Document-feature-matrix
“Content analysis is a research technique for making replicable and valid inferences from texts…” (Krippendorff 2004, p. 18)
In a political context, there is a large range of texts that can be used for content analysis (speeches, party manifestos, legal texts, treaties, meeting notes, journalistic articles, etc.)
Overview over text-as-data methods
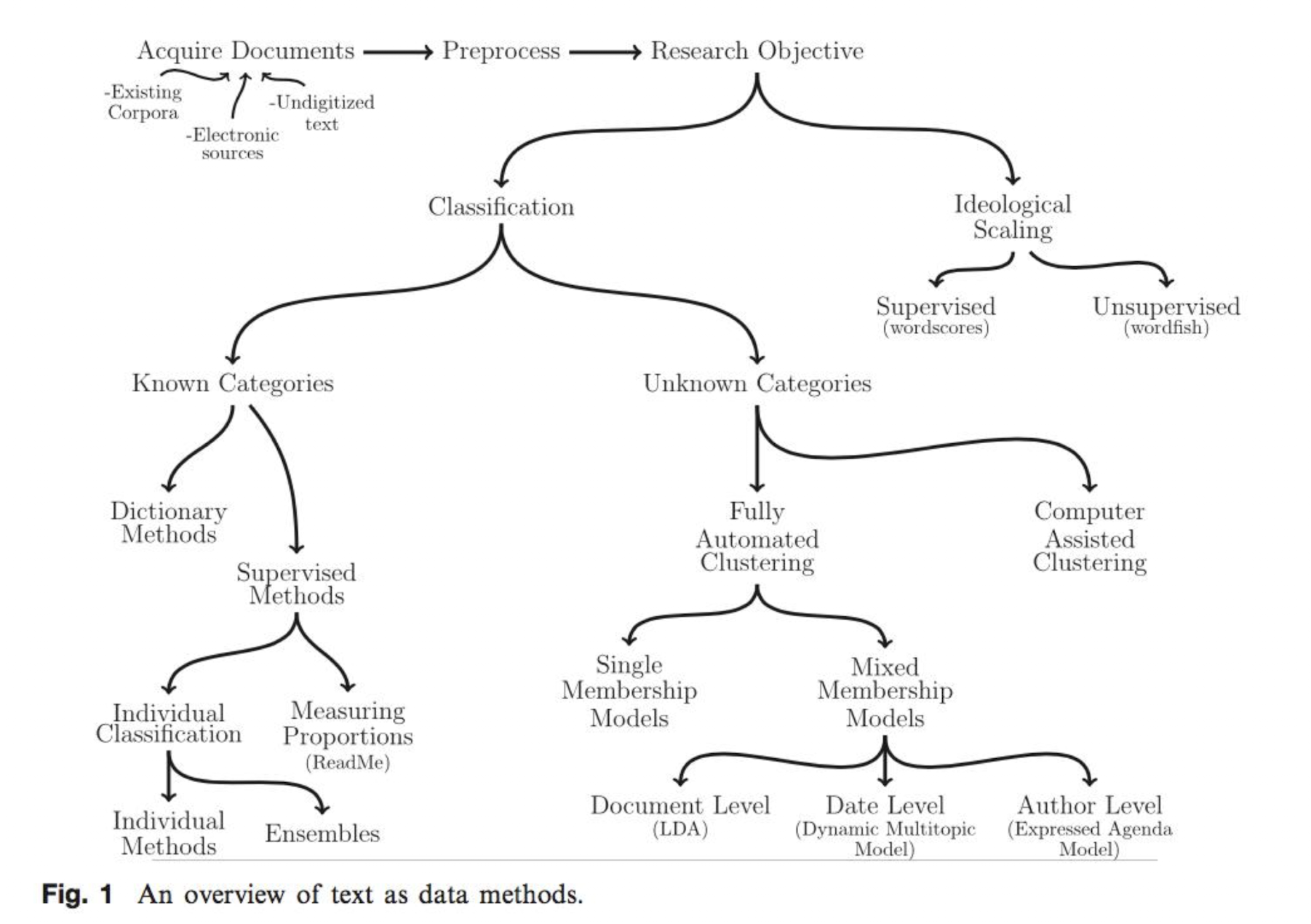
The different methods of content analysis have one of two goals:
- Categorisation / Classification
- Ideological scaling (e.g. of Party Manifestos)
They can either be:
- supervised (categories are known beforehand)
- unsupervised (categories are unknown)
| Goal | Supervised methods | Unsupervised methods |
|---|---|---|
| Categorisation | ||
| Ideological Scaling | Wordscore → reference text needed | Wordfish → works without reference text |
Wordscores
The goal of the wordscores method is to identify the unknown position of a text on a scale based on a reference text.
- Two types of materials: Reference texts and virgin texts
- Example: Place the content of party manifestos on the left-right-scale (with one of the positions known, other one not known)
1. Selecting the reference text according to some criteria
Criteria for the selection of reference texts are:
- Similar vocabulary
- Text should span the whole dimension that is studies (e.g. left-right-dimension)
- In the example of party manifestos, does that mean that you need to use texts from all parties as reference texts? → yes
- Highest number of unique words possible across the reference corpus
2. Calculating word scores for each word in the reference text
Overview
- Calculating the probability of reading the reference text when reading a specific word
- Calculating word scores for each word
- Computing the position of the virgin texts (incl. variance)
Substep 1: Probablity of reading the reference text when reading the word
Formula:
Reading:
- The probability of reading the reference text when reading the word is the
- relative frequency of word of the text (how often a word occurs in the text in relation to the total number of words) divided by
- the relative frequencies of word in all texts (sum over all texts)
Example
In two reference texts A and B:
- A: Word “nuclear” appears 10 times over 1000 words
- B: Word “nuclear” appears 30 times over 1000 words
If we read the word “nuclear” the probability of reading text A is 25 %.
Substep 2: Calculating the word score for each word on the dimension
Weighted sum = Probability of the first step is weighted by the position of the dimension
Formula:
- = Word score on dimension for word
- =Probability of reading the reference text when reading word (see above)
- = Position of reference text on dimension
Example
Text Position on left-right-scale for “nuclear” A -1 0.25 B 1 0.75 The first values in both of the products are the probabilities calculated in the first substep.
Supstep 3: Computing the position of the virgin texts
Formula:
The relative frequency of a word in the virgin text is multiplied with its respective word scores. This is repeated for each scored words (= words existing in the reference texts).
Formula:
- = Variance of virgin text on dimension
- = Relative frequency of word in virgin text
- = Score of word on dimension = wordscore (substep 2)
- = Score / position of virgin text on dimension (substep 3)
Within the brackets: Difference between the position of each word on the dimension and the position of the whole text
The caclulated variance quantifies the uncertainty of the position calculated in the first part of this step. Based on this, the standard errors and confidence intervalls can be calculated.
3. Rescaling the scores of the new text to the scale of the reference text (optional)
This accounts for the lengths of the text
Wordfish
- Unsupervised
Application in R
Wordscore
1. Preparation
- Transform text file into a dataframe using the
readdtextfunction. This creates a dataframe in R with two columns (doc_ididentifying the text andtextwith the actual text)- How to define the references and virgin texts?
- At this point, all the texts are simply included.
- Create a corpus object using the
corpusfunction. This is basically just a transformation step. - Create tokens using the
tokenfunction. This transforms each meaningful word into a single data point)- The function includes some options as the removal of punctuation and symbols. These can be removed because they don‘t have any substantial meaning for the analysis.
- Assumption: Bag of words → what matters are the frequencies of words, not their order
- Create a document-feature matrix using the
dfmfunction- To be able to better read the matrix it can be transformed into a data frame.
- The matrix shows a row for each word, each column shows the absolute frequencies of each unique word in the different texts.
2. Removing stopwords and stem terms
3. Analysis
-
topfeatures: Shows the most frequent words -
textstat_frequency -
textplot_wordcloud -
Assigning the reference scores
- First, create an object simply containing the scores. Reference texts get assigned the respective score, virgin texts get assigned
NA - Then, the scores are attached to the respective texts
- First, create an object simply containing the scores. Reference texts get assigned the respective score, virgin texts get assigned
-
Calculating the wordscores using the function
textmodel_wordscores -
The wordscores can then be extracted from the created object and for example attached to the previously created data frame
-
Getting the positions with
predict+ option to rescale
Output:
con92.txt con97.txt lab92.txt lab97.txt ld92.txt ld97.txt
10.530371 9.998495 9.070044 9.661368 9.139585 9.509094 4. Manually calculating a word score
term con92.txt lab92.txt ld92.txt economic
1 new 177 86 72 10.09579
2 welfare 9 0 1 15.81002 con92.txt con97.txt lab92.txt lab97.txt ld92.txt ld97.txt
total_words 28991 21142 11442 17570 17487 13945
unique_words 4027 3161 2361 2994 3133 2410
mean_frequency 7.199156 6.68839 4.846252 5.868403 5.581551 5.786307
median_frequency 2 2 1 2 1 2 Calculating the wordscore for the word “new”:
- Calculate the relative frequencies of each word in the reference texts
| Text | “new” | Total words | Relative frequency | Dimension (known before) |
|---|---|---|---|---|
| con92 | 177 | 28991 | 177/28991 = 0.0061 | 17.21 |
| lab92 | 86 | 11442 | 86/11442 = 0.0075 | 5.53 |
| ld92 | 72 | 17487 | 72/17487 = 0.0041 | 8.21 |
- Calculate the probability of reading a reference text given you read the word “new”
Following the same logic, the probability for lab92 is 0.4237 and 0.2316 for ld92.
- Calculate the word score of the word “new” on the Economic Policy Dimension using the probability and the score on the dimension for each text.